Yes we can secure C: an example
Stop being so difficult about it.

We can trivially upgrade C to be a memory-safe language, but people are unwilling. They want to create new, elegant, incompatible languages rather than dealing practicalities.
An example is this tweet about adding a length check in a Linux driver. I don’t what the person tweeted this intends, but it’s a spaghetti code fix to a simple problem.
The underlying program is that that the file as a function chap_basse64_decode() with the following protoype:
static int chap_base64_decode(u8 *dst, const char *src, size_t len);This can lead to the classic problem of a buffer overflow, because a hacker may find a way to supply a very long src string that will write too many bytes into the dst buffer, overflowing it.
The fix is the following, to check the length of the dst buffer before calling the function to make sure it won’t overflow. BASE64 decoding writes 3 bytes for ever 4 bytes of input, stopping at either the end of the source string, or at the first ‘=’ sign.
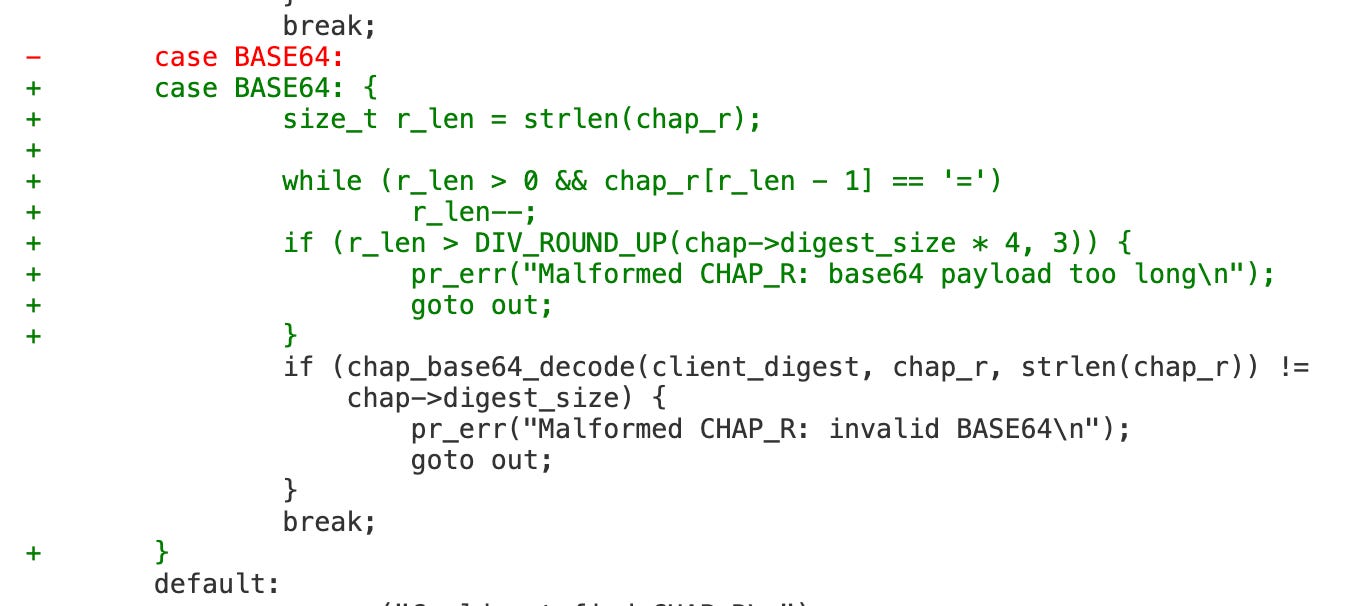
This fragile spaghetti code.
The correct fix is to simply change the decode function, adding something like a dstmax parameter.
static int chap_base64_decode(u8 *dst, size_t dstmax, const char *src, size_t len);Then, the code inside that function needs to be changed to check the buffer. Currently the code looks like this:
u8 *cp = dst;
. . .
*cp++ = (ac >> (bits - 8)) & 0xff;You’d change it to something like:
u8 *cp = dst;
u8 *cpmax = dst + dstmax;
. . .
if (cp >= cpmax) return 0;
*cp++ = (ac >> (bits - 8)) & 0xff;This is how all such functions should be written in C.
If your function is writing to a buffer, then you need to add bounds information to the function so that it can be checked. It needs to be checked in the most obvious manner such that code reviewers, static analyzers, and AI can verify that yes, you did indeed check the bounds information to prevent an overflow.
If a function is missing bounds information, then it’s incorrectly written. AI tools and static analyzers should be triggering warnings on this.
One of the reason this isn’t done is that people have it in there heads that such problems need to be handled “elegantly”, like they do in Rust or Zig or C++ with smart-pointers. Passing two parameters like this is ugly.
So what? Ugly gets the job done. Trying to rewrite the language is not getting the job done.
Right now AIs are finding a ton of such bugs in old C code, like the Linux kernel. People need to pay attention to this class of bug and be told that the correct fix is to refactor the function prototype itself, to add a bounds check parameter like dstmax.
With AI, this is a fast fix that you can vibe code, asking AI to change the function to add the bounds checks, and then to point to all callers and tell you either what the appropriate bounds information is to pass into the function, or that the bounds information isn’t easily knowable.
You have to verify the AI made the correct changes, so you aren’t excused from needing to understand the code in depth, but it’s fast work.
Yes, about 10% of the time, you can’t fix the caller, because the caller doesn’t know the bounds information, either. This is going to point to a more extensive change you can’t vibe code. I don’t have answer to that. I just have answers to this particular problem.
Judicious use of AIs by either attackers or defenders is eventually going to find these problems, but you can speed up the process with simple changes to the C programming language.
The reason this has festered for so long is that people want elegant fixes to the language, like smart pointers that know their own bounds. This doesn’t work. The overriding rules here are:
code with the new language features need to still compile correctly on old compilers
library APIs likewise need to be stable in the face of language feature changes
The solution to this problems is fugly macros. For example, if this chap_base64_decode() were a library function, we do the following:
int chap_base64_decode_SEC(u8 *dst, size_t dstmax BOUNDS(dst),
size_t dstmax, const char *src, size_t len) REPLACES(chap_base64_decode);The macros hide language changes, allow FORTIFY_SOURCE to automatically fix old code, and most importantly, allows static analyzer provide a path to refactor a code base. Meanwhile, such new code continues to work on all older compilers.
Conclusion
First of all, the correct fix to any buffer overflow vuln is to refactor the function prototype to check its own bounds. This example of adding spaghetti code is a bad fix.
Second of all, such bugs are easily found with AI. Attackers and defender are going to quickly make these rare in old code. We don’t need to do anything.
Third of all, there are easy things we can do to compilers or static analyzers to make refactoring bounds checking fairly easy.
As a former assembler and C programmer, I'd say there's another obstacle to this simple fix: it's not always necessary. Suppose a program has telephone numbers or postal codes as inputs and verifies them, including length. Checking the length of known data every time it gets passed around is a waste of time.
C is supposed to be simple code, minimalist. Unnecessary redundant length checking goes against that ethos. So what if it takes in-depth study and analysis to verify this; that's what makes C programmers special. They program smart instead of relying on crutches like extra unnecessary arguments or fancy-schmancy languages with built-in redundancy.