More IPv4 address parsing
Some notes


Recently, Daniel Lemire had a blogpost pointing out that AI produced surprisingly fast code for parsing IPv4 addresses. As a “parser” guy, I have some comments.
The summary is this:
his benchmarks were flawed, though the code is indeed fast
it’s fast because of good compilers and good CPUs, not good AI
let’s look at some other algorithms
Large test sizes
The reason the AI code appeared so fast is that his benchmark was flawed. He only parsed 15,000 addresses, instead of a larger test like 1,500,000 addresses.
Instead of his original benchmark taking 4.4 nanoseconds per IP address, it now takes over double that, 11.05 nanoseconds. These are per address, calculated by total time divided by the number of addresses.

One possible reason is that the larger test size is evicted from the fast L1 cache into the slower L2 cache. You can see that with the memcpy part of the benchmark, because L2 bandwidth is lower.
But this shouldn’t be a latency problem. CPUs predict access patterns, so should automatically put something into the L1 cache before it’s needed. Also, you can fit 10 addresses into a single 128-byte cacheline, so it would only impact 10% of the addresses.
I’ve concluded it’s probably branch prediction. Modern CPUs have added branch prediction algorithms that depend upon data accesses, which will get disrupted when data access patterns become too large. In other words, branch prediction “overfit” the original test case size.
A failed branch prediction can add around ~3 to ~4 nanoseconds. I tracked some low-level CPU hardware counters that suggest there are 1.7 branch misses, which roughly lines up with the extra 6.5 nanoseconds in time.
The hardware counters are flaky, and speculative execution mitigates a lot of the cost of a miss, so I’m not really confident in this conclusion.
I wrote my own code to test this, which I describe in a section below.
The conclusion is simply that a short test doesn’t reflect real-world behavior, you need a large test case. The size of that test case matters, simply repeating a short test case isn’t sufficient to properly measure this. In real world parsing, input is constantly changing, so wouldn’t match the short test case, but the long.
Smart compilers and CPUs
The reason that AI generated code is fast is because modern CPUs have a lot of tricks, such as the data-dependent branch prediction mentioned above.
Remove those tricks and go back to an old CPU, and the benchmark doesn’t show such an advantage. It’s not bad, it becomes merely average.
There’s a similar story with compilers. Using modern compilers to build code for old CPUs still improves their speed. The recognize common idioms, replacing the code you think you wrote with something more efficient. The website GodBolt.org is does a great job compiling code for you on virtually all compiler versions so that you can see the difference in how modern compilers generate code compared to old ones.
AI produces average code. Modern compilers and CPUs have optimized the s**** out of average code, making it perform fast. It’s to the point where you should ask the AI to produce typical code, and not try to steer it toward weird optimizations, because that’ll likely slow things down instead of speed things up.
My fastip project
I’ve created a project, fastip, to benchmark this against other algorithms. I’ll describe the other algorithms below.
I implement a bunch off different algorithms, and then benchmark mark them twice, once with the short test-case, and again “+” with the long test case. The AI generated algorithm is the first one, though I ported it to C from C++, and it appears a bit slower, at 5.4 nanoseconds per IP address, going to 11.9 nanoseconds for the larger test case..
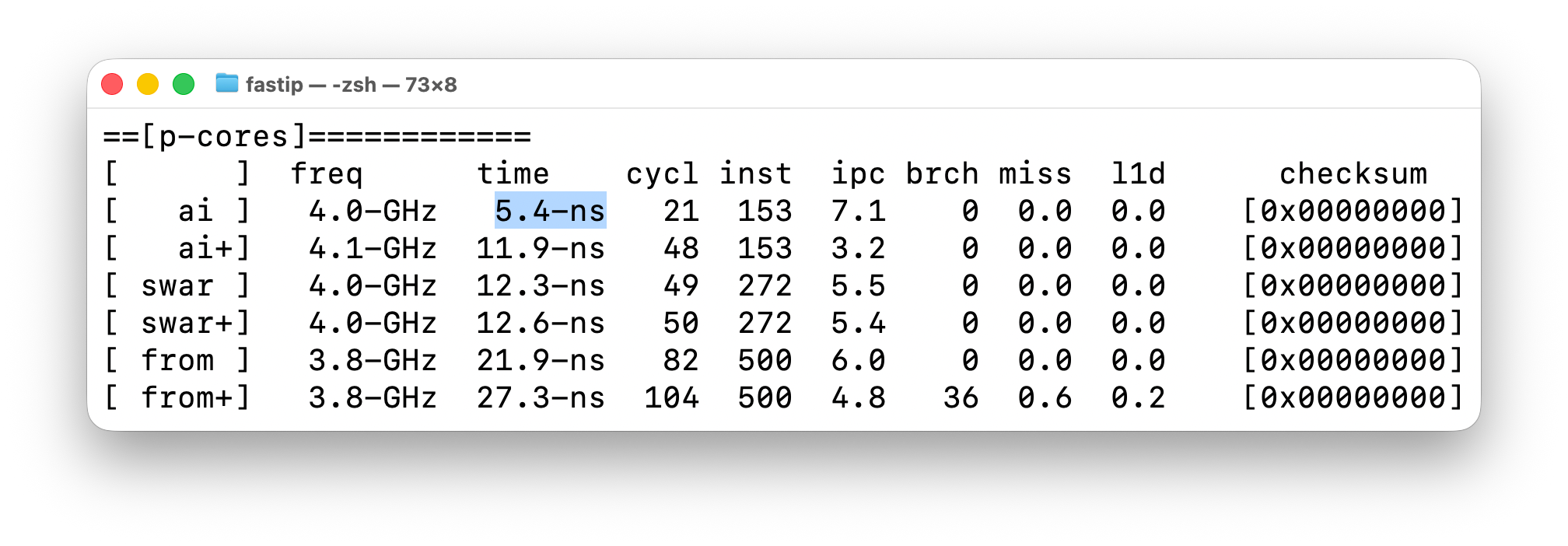
The hardware counters are flaky, so it’s not correctly reporting branches or misses.
I changed the test to also run on the e-cores. Modern CPUs have both powerful, power hungry cores (p-cores) and efficient, slower cores (e-cores). My tests also run on the other cores, where I get better hardware counters:
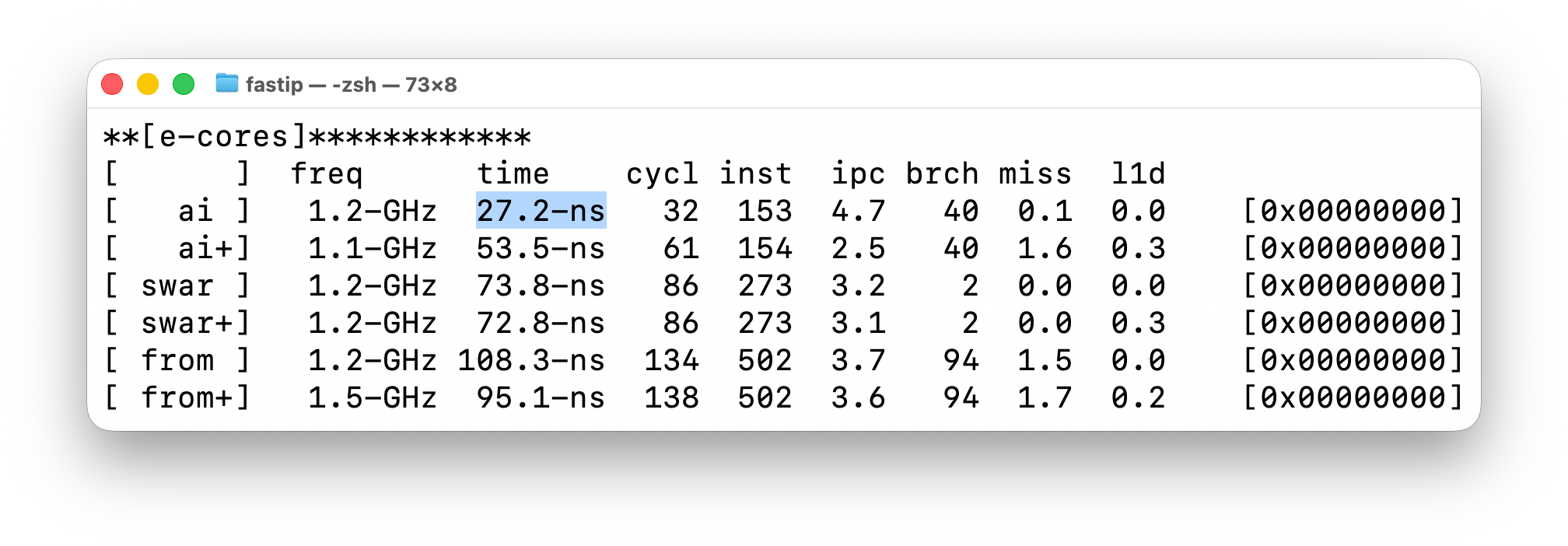
As you can see, the original algorithm now takes 27.2-ns vs. 5.4-ns. That’s because the cores are running at a slower clock rate (1.1-GHz instead of 4.1-GHz), but also because they are slower per clock cycle (4.7 IPC instead of 7.1 IPC).
The thing to note is that I’m getting branch/miss hardware counters to the right. I can see that the algorithm has 40 branches, and that in the larger data set, 1.6 branch misses.
This confirms branch misses are a problem, but introduces other problems. Branch misses are roughly the same cost, ~3ns to ~4ns, so doesn’t explain the 25ns slowdown we see here.
Another way I tested this is using an algorithm that gets rid of all branches. I’ve marked this in the screenshot below, in the [brch] column, where using SWAR techniques, the number of branches go from 40 to 2. And those branches come from simply calling the parse function.
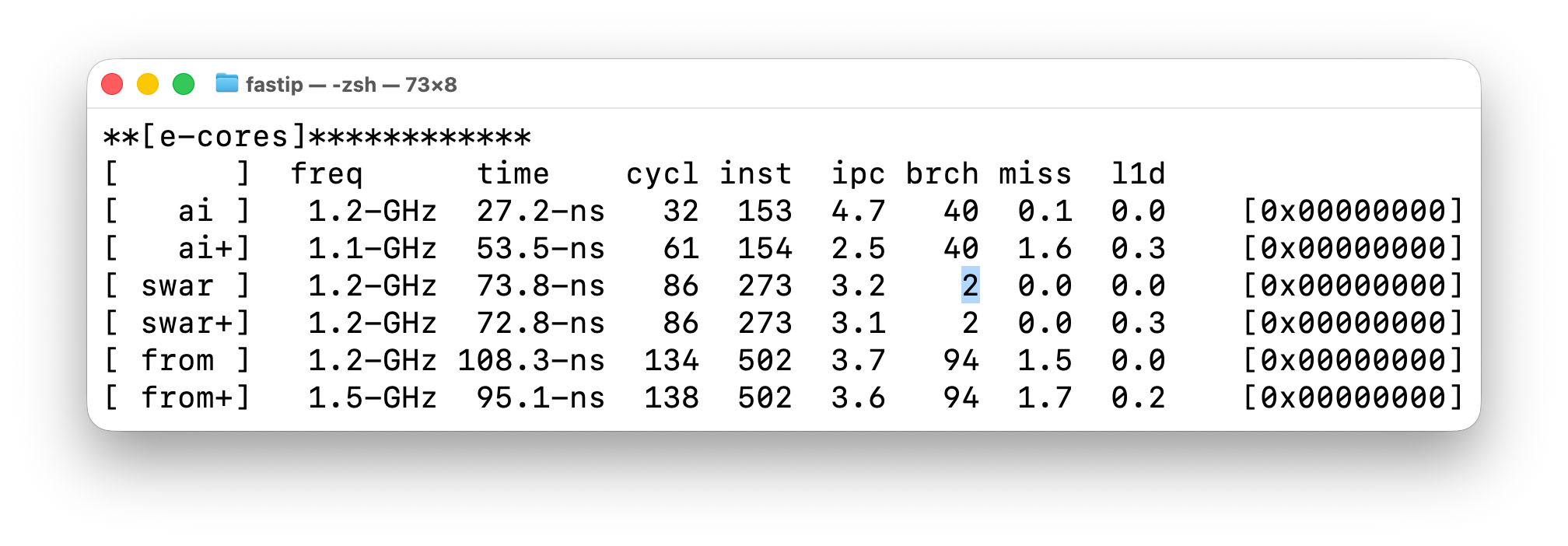
By “branches” we mean all “if” conditional statements, “for” or “while” loops, “gotos”, or “function calls”. By “SWAR” we mean using techniques from SIMD/GPUs applied to normal C code, which among other things, removes branches. You can go read the code if you are interested to see how we can get rid of such things.
The [swar] algorithm for parsing addresses experiences no slowdowns when moving to the larger data set, implying that indeed, branches could be the problem. It has no branch mis-predictions because it has no branches.
Similarly, the next algorithm, [from], is branch heavy, with branch misses regardless of input size, again implying this could be related to the problem.
I have a bunch more algorithms. These are vibe coded, and not particularly optimized. Like the [swar] algorithm (also vibe coded), they are meant simply as a different way of looking at how the CPU operates rather than trying to be fast.
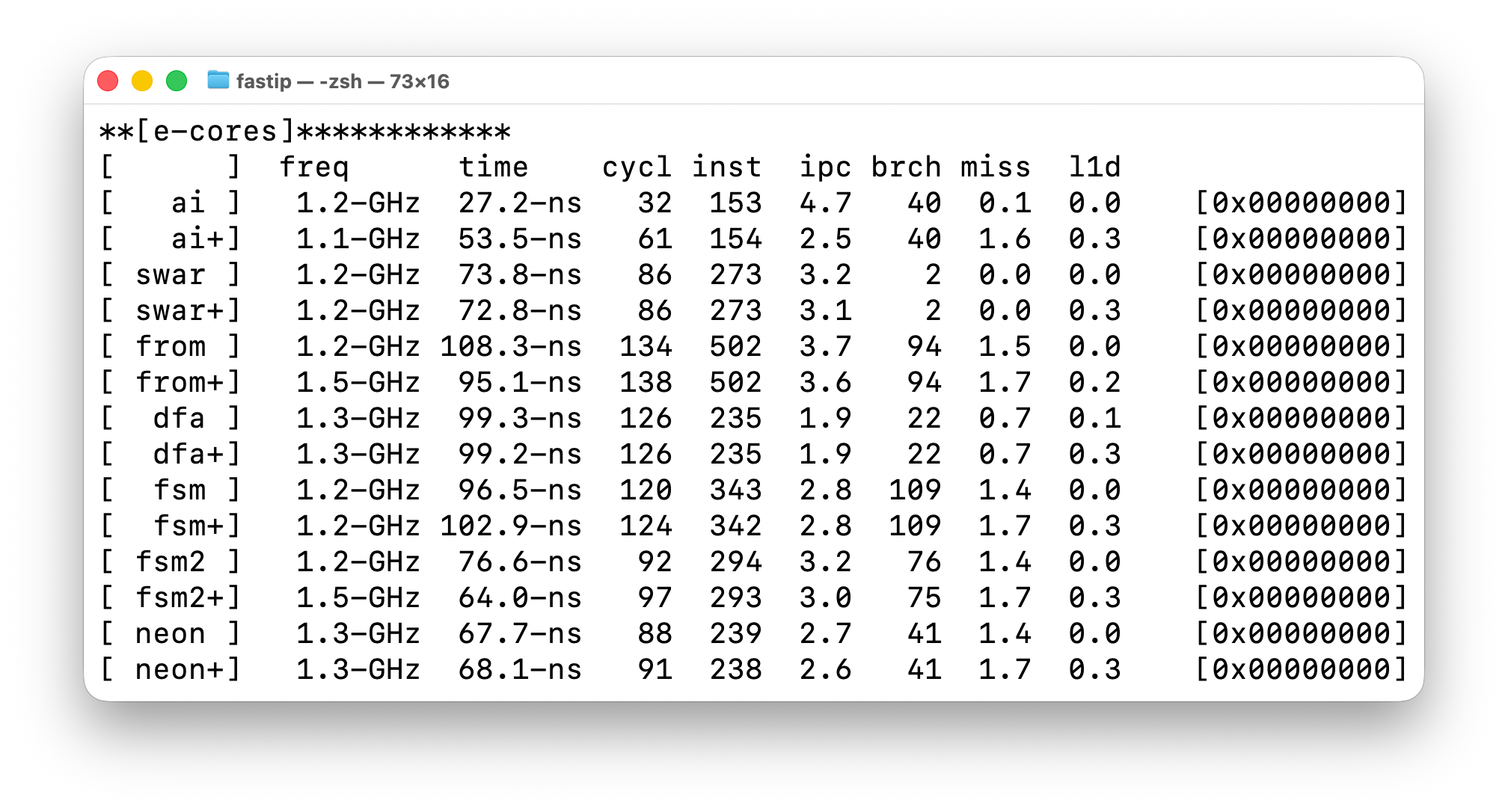
Three of these, [dfa], [fsm], and [fsm2] are different ways of using state-machines as parsers. They are unoptimized and therefore slower, but when optimized, they are usually the fast way of parsing. The reason is that they also optimize the surrounding code that calls them, namely, handling fragmented input.
A typical use of parsers first reassembles fragments then does an initial pre-parse, such as finding the end-of-line in text. State-machines avoid this.
Then, within the state-machine framework, you can use non-state-machine techniques to optimize things, getting the benefit of both worlds.
Conclusion
The high instructions-per-clock of 7 IPC from the original blogpost made me suspicious. I found that the size of the input test case matters. I’m still unsure why it matters, though I suspect it’s branch prediction related. I created a project that investigates this.
Why don't people build fast IPv6 parsers?